With the increasing amount of data at hand, there has always been development of ways to handle such large scale data, organize it, compute on it and ensure practicality. MapReduce is a revolutionary model which allows you to do data parallel computations on cluster machines while providing task scheduling, fault tolerance and load balancing. But there are some application where MapReduce falls short. According to the super famous Spark introducing paper by Zaharia et. al., such applications are those which use a working set of data across multiple parallel operations. This includes two use cases, iterative jobs (basis of most machine learning algorithms) and interactive analytics (SQL querying). Spark is a cluster computing framework which supports working on these cases, while providing all the benefits of MapReduce.
RDD
Resilient Distributed Datasets (RDDs) represent a read-only collection of objects partitioned across a set of machines that can be rebuilt if a partition is lost.
One can imagine RDDs as the backbone of Spark’s functionality which is simply a collection of objects distributed across clusters. Its fault tolerant and we perform various parallel tasks on the RDD. An RDD can be created by parallelizing a collection or by reading from an external source.
In general, there are two types of operations that can be performed on RDDs, transformation and actions. Imagine you have an RDD. A transformation is an operation wherein you transform the RDDs data into another form. For example a filter function which gives you the entries of the RDD with an even Id number. The tricky part is that Spark doesn’t actually perform a transformation on the RDD immediately. Instead it prolongs the task to a later time. This is called lazy evaluation.
Why would Spark behave lazily ? Imagine you called upon multiple transformations on an RDD, one after the other. Now Spark will create an directed acyclic graph (DAG) of these transformations. It will rearrange these tasks in order to optimize the execution flow and choose the best possible transformation path. Imagine you have map operation followed by a filter. Spark will rearrange these operations as filtering would reduce the amount of data undergoing a map operation.
The transformation tasks actually take place when an action operation is called. For example, when the user submits a Spark job for a collect operation, Spark will perform all the previous transformation tasks in the optimized manner, and send the results to the driver function. Also, RDDs can be cached at any time to persist the data in memory or disk. This is really handy when performing a long set of interrelated operations.
Driver and Executors
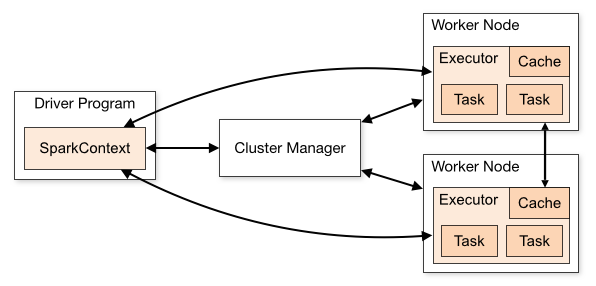
Driver is the main program which creates partitions, distributes and schedules tasks and manages the outputs of individual worker nodes. Executors are worker nodes’ processes in charge of running individual tasks in a given Spark job. Once the job is complete, they send the results back to the driver.
Spark Stack
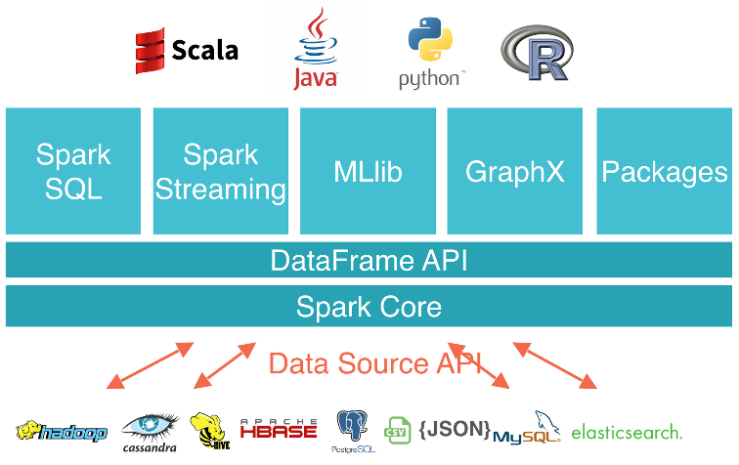
Spark offers a whole range of integrated components which form the Spark stack. Spark SQL allows you to perform SQL-like data analytics on distributed data. With Spark Streaming, you can do real-time processing of live data streams. MLlib is the machine learning library providing most of what you’ll need for learning insights from the data on Spark. GraphX is Spark‘s API for graphs and graph-parallel computation.
The main selling point of Spark is how efficiently it manages data in the memory instead of the disk. This clearly doesn’t mean that ALL the data is stored in the memory. But Spark finds a way to organize the operations in parallel and optimize them, keep only the required amount of data in memory and manage the computations to provide greater performance improvements.
