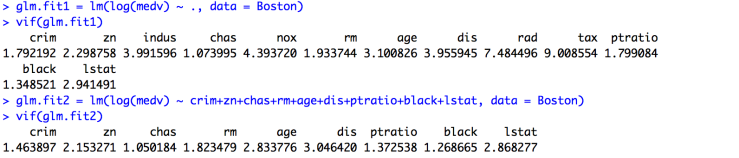
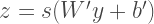Have you ever noticed how a professional sketching artist uses multiple types of pencils for his work ? Each pencil has a different features and used to achieve different shades and details. The world of databases is very similar. You have many databases which specialize in different aspects of data storage and functionality and hence they provide you with additional use cases which others couldn’t have.
Polyglot persistence is a term used in the database community to describe that when using a database, it’s best to choose the type of database based on the usage and functionality. A standard example is of e-commerce companies. They deal with many different types of data. Storing all the data in one place, would require a lot of data conversion to keep the format same, which would inherently lead to a loss of information.
Historically, RDBMS databases have ruled the industry. But, necessity is the mother of invention. Though NoSQL databases have existed before, they never got a solid ground until the explosion of the web required companies like Google and Facebook to look for alternatives outside the classic relational storage realm. Now, NoSQL are ubiquitous in the time of big data.
Is there a metric to understand NoSQL distributed storage systems better ? The famous CAP Theorem. Also called Brewer’s theorem after Eric Brewer, the CAP Theorem provides a metric to classify and comprehend the attributes and limitations of NoSQL systems. It states that no distributed computer system can satisfy ALL of these three features:
- Consistency – every read would get you the most recent write
- Availability – every non-failing node will return a response
- Partition Tolerance – the system will continue to work if network partition occurs
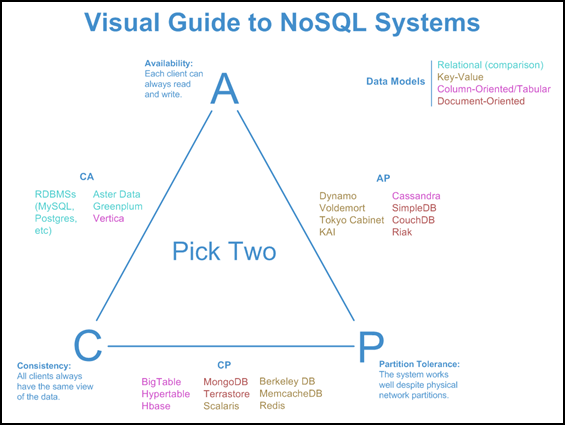
So, this means that all NoSQL databases can satisfy two out of these three features. Deciding which database to use comes down to the product requirement. Let’s cover some common databases belonging to different categories.
Cassandra
Cassandra is a database created by the folks at Facebook. It’s a column-family store. Column-family databases store data in column families as rows that have many columns associated with a row key. Column families are groups of related data that is often accessed together. A column family is analogous to a table in RDBMS. The difference is that you don’t need to have the same columns for all the rows. Other examples of such stores are HBase and Hypertable.
Cassandra is highly scalable. There is no single master, so scaling up is just a matter of adding more nodes to the network. Cassandra falls in the AP category. It’s designed to be high on availability and partition tolerance, but have the architects have to negotiate on consistency. It relies on a notion of eventual consistency. The data on a node, though not the latest now, will eventually be replaced by the most recent one.
Redis
Key-Value store. A hash table. A key-value store is a very simple NoSQL database with options for fetching, updating or deleting a value for a key. Redis supports storing lists and sets and can do operations like range, union, diff, intersection.
Redis is an in-memory store. This enables it to be a perfect option for high read and write rates, but limited to the size of data that can fit inside memory. Despite being a NoSQL system, it is difficult to grade Redis according to the CAP theorem. This is because it is generally used in a single-server deployment. One can create a Redis cluster using a master-slave scheme, but the behavior of it would depend on how it is configured. This blog post explains the functionality of Redis to great extent.
Titan
Titan is a graph database. Just like a graph, these databases have nodes and edges. The edges capture the relationships between node-like entities. Entities and relationships have properties.
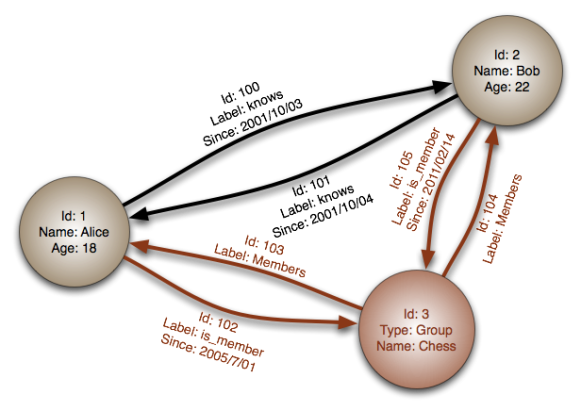
Titan is designed to support the processing of graphs so large that they require storage and computational capacities beyond what a single machine can provide. Titan supports Cassandra, HBase and BerkerlyDB as its backends. Their tradeoffs with respect to the CAP theorem are represented in the diagram below.

There is a fourth kind of NoSQL database, called document store. Expanding on the idea of a key-value store, document based databases store more complex data in the form of ‘documents’ as values assigned to a unique key. It’s most common examples are MongoDB and CouchDB.
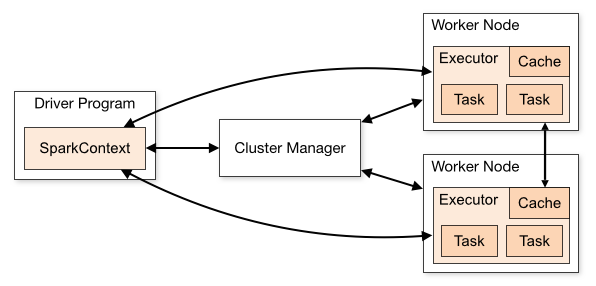
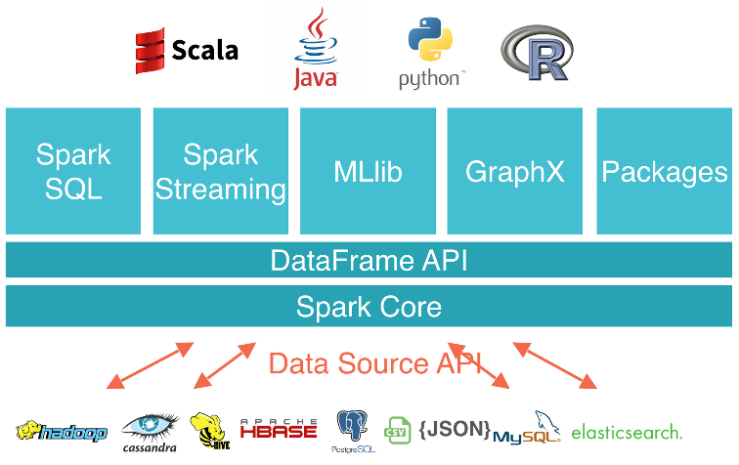

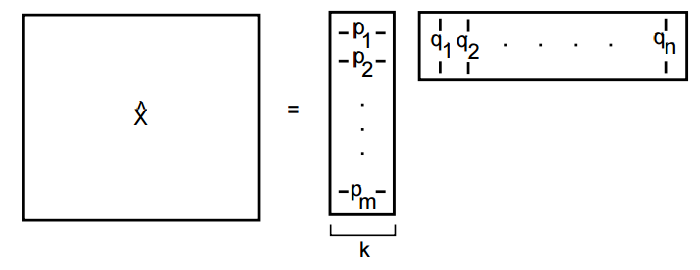

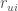 is the observed ratings. One approach is to use Alternating Least Squares. If ‘fixes’ one of
is the observed ratings. One approach is to use Alternating Least Squares. If ‘fixes’ one of 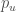 and
and 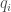 , and minimizes the other. Then is ‘alternates’ by fixing the second one and minimizing the former. This alternation between which matrix to minimize is the reason of ‘alternating’ in the name. Clearly, we can add regularization terms to the loss function for better updates. Apache Spark’s MLlib has an
, and minimizes the other. Then is ‘alternates’ by fixing the second one and minimizing the former. This alternation between which matrix to minimize is the reason of ‘alternating’ in the name. Clearly, we can add regularization terms to the loss function for better updates. Apache Spark’s MLlib has an