This post is aimed at folks unaware about the ‘Autoencoders’. Some basic neural network knowledge will be helpful, but you can manage without it. This post is an introduction to the autoencoders and their application to the problem of dimensionality reduction.
What are autoencoders ?
These are an arrangement of nodes (i.e. an artificial neural network) used to carry out a straightforward task, to copy the input to the output. The input that is given in, is transformed to a ‘code’, and then the input is again reconstructed from this ‘code’. Weird right ? No. The catch is that this conversion from the input to ‘code’ and then its reconstruction allows the autoencoder to learn the intrinsic structure of the inputs. Basically its learning your inputs, and without any labels (unsupervised learning).
Technically, an autoencoder takes an input x and maps in to the internal representation y.

Here, W is the weight matrix and b is the bias. The vector y is the hidden representation or the ‘code’ and is then again transformed to recreate the inputs.
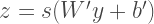
W’ and b’ are the weight and bias matrices. The function s in the above equations is the function of the nodes. The most common one is the logistic or sigmoid function. The point is to have the transforming function as a non-linear one like sigmoid, tanh, etc. I’ll get to the logic behind this soon.
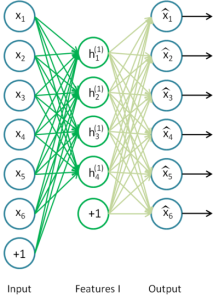
This image should help in consolidating a mental picture of what you read above. So, you can imagine an autoencoder as and encoder + decoder. The input layer + hidden layer (the one in the middle) perform the role of encoding the input to an hidden representation. The hidden layer + output layer do the job of undoing the encoding, that is decoding. The weight matrices give the weights of the connections between each nodes of a different layers. The training of the autoencoder is nothing but adjusting the weights such that the reconstruction error is minimised.
What’s this error thing ? This error can be measured in many ways, mainly to account for the distributional assumptions on the input given the code. The most common one is the least squared error, another important one is cross-entropy error. Its nothing but a fancy term for how different the reconstructed output is from the inputs.
And how do you expect to train the autoencoder ? Oh you mean adjusting the weights! Thats where the mystical backpropagation algorithm comes in. 🙂 You may take some time get you head round this one, so don’t panic if you get lost in its derivatives and gradients. By the way, thats not the only way, but certainly an important way.
What has an autoencoder to do with dimensionality reduction ?
Dimensionality reduction is a huge topic. You can find loads of material on it. Basically, its reducing the dimension of the input data for better analysis, better visualisations and hence an overall better understanding of the data. You can’t underestimate how important that can be.
But don’t we have loads on dimensionality reduction algorithms ? Absolutely! There is the classic PCA which probably we all start with. But the autoencoder beats the PCA (I’m not propagating replacement of PCA with the autoencoders).
If you haven’t realised it yet, the autoencoder is reducing the dimensions of the data by transforming the input into the ‘code’ layer (the middlemost hidden layer obviously has lesser nodes than the input layer). And given enough depth and better training, the autoencoder does a pretty good job at capturing the essential statistical knowledge present in the input data. Also, the autoencoder uses a non-linear function and is able to gather more, unlike the PCA (which is a linear algorithm, and may not be able to cater to the intricacies of all types of datasets).
What the earlier figure showed was a simple three layer autoencoder. With a linear function, it does no better a job than the PCA. It learns the hidden layer as a linear function of the data with the least squared error minimized, which is exactly what the PCA does. Now look at the next figure!
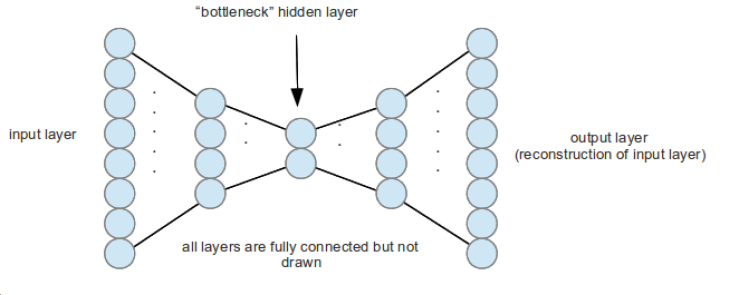
Instead of having just one encoding and decoding layer, you can have multiple layers doing each of the role. This is what I meant by depth. The resulting autoencoder is called a stacked autoencoder. And now if you throw in an unsupervised neural network model to further tweak the layers’ weights before fine-tuning them by backpropagation, you get better training.
If you go ahead and take a course on deep learning and neural networks (or atleast go through my hyperlinks and references), you’ll soon realise that all these models are nothing but mathematical equations. Its quite fascinating what mathematics can do!
I want to try the concepts of stacked autoencoders with better pre-training and test them against images. Lets see, hopefully in the next post!
I hope I managed to bring neural nets (or machine learning) to the attention of some folks! Thanks !
Further reading / References:
- http://deeplearning.net/tutorial/dA.html
- http://alexminnaar.com/deep-learning-basics-neural-networks-backpropagation-and-stochastic-gradient-descent.html
- http://deeplearning.net/tutorial/SdA.html#stacked-autoencoders
- http://www.cs.toronto.edu/~hinton/science.pdf
